Context is All You Need: The AI 2025 Story
2025 wasn't the year AI models got dramatically better. It was the year we learned how to use them properly. Models are increasingly commoditized—context prompts, retrieval, memory, reasoning, and tools became the real leverage.
TL;DR
2025 was not just the year when AI models got dramatically better; it was also the year we learned how to use them properly.
- Models are increasingly commoditized
- Context prompts, retrieval, memory, reasoning, tools became the real leverage
- Reasoning models, agents, and memory systems are all ways of generating better context
- Fine-tuning fell out of favor; context engineering outperformed it
- Sales is one of the hardest real-time context problems, which makes it the right proving ground to solve
- AmpUp.ai is fundamentally a context engineering platform, not a voice or agent company
Introduction
Three years ago, I wrote a piece demystifying the conceptual stack behind ChatGPT . The response revealed something important: a massive group of practitioners was hungry for first-principles explanations of the shifts driving our industry.
This piece follows a different objective.
It’s about making sense of what happened in AI over the last twelve months, a year that fundamentally shifted where the action is.
If I had to summarize 2025 in one sentence:
We stopped obsessing over the model and started obsessing over context.
If you’re still thinking about AI primarily in terms of models, you’re already behind. The teams that trained the best models in 2023 are not the same teams winning in 2025.
The skill that mattered then (training) is not the skill that matters now (orchestration).
This piece explains:
- why that shift happened,
- what replaced the old paradigm, and
- what it means for anyone building with AI.
To understand why context became the bottleneck, we need to start with the moment models stopped being scarce.
The DeepSeek Wake-Up Call
January 2025. A Chinese AI lab called DeepSeek releases a model that matches frontier performance at a fraction of the assumed cost. The AI community had internalized a narrative: competitive models required billions of dollars, massive GPU clusters, resources exclusive to a handful of companies.
DeepSeek broke that narrative.
The key papers are DeepSeek-V2 (May 2024) and DeepSeek-V3 (December 2024). The technical ideas illustrate a broader point: cleverness can substitute for brute force.
Two ideas mattered:
-
Multi-Head Latent Attention (MLA) attacked the memory bottleneck by compressing key/value vectors into a lower-dimensional latent space, reducing KV cache memory by over 90% while preserving quality. DeepSeek compressed these vectors into a lower-dimensional latent space, learning during training what information is essential to preserve. If original KV vectors are dimension d and you compress to dimension c where
c << d, you reduce memory by a factor of d/c. They reported 90%+ compression while maintaining quality. -
Mixture of Experts (MoE) attacked the compute bottleneck by activating only a subset of parameters per token. DeepSeek-V3 has 671B parameters, but uses only ~37B per token at inference.
The combination meant DeepSeek trained competitive models for under $6 million.
This raised an uncomfortable question: if the model itself is commoditizing, what actually matters?
The 2025 Thesis
The model is the engine. Context is the fuel.
The weights are frozen after training. What you can change is everything you feed in: prompts, retrieved documents, conversation history, system instructions, examples, memory. That’s where the leverage lives.
- System prompts, instructions, examples
2. Retrieved context- Documents, RAG (Retrieval-Augmented Generation), search results
3. Generated context- Reasoning traces, scratchpads, chain-of-thought
4. Lived context- Memory, interaction history, environment observations
Every breakthrough of 2025 improves one of these four. Reasoning models improve generated context. Memory systems improve lived context. RAG and agents improve retrieved context. Prompt optimization improves static context.
The model stays the same. The context gets better.
| Level | Paradigm | Era |
|---|---|---|
| 1 | Prompt Engineering | 2023 |
| 2 | RAG & Vector Databases | 2024 |
| 3 | Reasoning & Test-Time Compute | Early 2025 |
| 4 | Context Orchestration & Advisor Models | Late 2025+ |
Most teams are still at Level 2. The frontier has moved.
Once models commoditized, the real innovation shifted to everything wrapped around them.
Breakthroughs of 2025
1. Reasoning Models: The Model Talking to Itself
The first major theme of 2025: reasoning models. OpenAI’s o1 arrived in late 2024. DeepSeek-R1 followed. Anthropic, Google, and others shipped their own.
The core idea: instead of outputting an answer immediately, the model generates a chain of reasoning first, then produces a final response based on that reasoning.
The technical roots of this idea stretch back several years but came together decisively in 2025.
- Chain-of-Thought Prompting (Wei et al., 2022) showed that explicitly asking models to reason step by step dramatically improved performance on multi-step tasks.
- Let’s Verify Step by Step (Lightman et al., 2023) demonstrated that training models to check intermediate steps increased reliability.
- Scaling LLM Test-Time Compute (Snell et al., 2024) formalized a new tradeoff: model capability depends not just on model size, but on how much computation you allow at inference time.
Here’s what took me a while to appreciate: reasoning is just the model generating its own context.
Reasoning models made LLMs appear smarter by making them patient.
When you ask a reasoning model a hard question, it writes itself a scratchpad. It breaks down the problem, considers approaches, catches its own errors. That scratchpad becomes context for generating the final output.
Consider a math problem: “A store sells apples for $2 each and oranges for $3 each. If I buy 5 pieces of fruit and spend $12, how many of each did I buy?”
A standard model might pattern-match and guess. A reasoning model generates:
Let me set up equations. Let a = apples and o = oranges.
I know: a + o = 5 (total pieces)
And: 2a + 3o = 12 (total cost)
From the first equation: a = 5 - o
Substituting: 2(5-o) + 3o = 12
10 - 2o + 3o = 12
o = 2
So a = 3
Let me verify: 3 apples ($6) + 2 oranges ($6) = $12 ✓Each line becomes context for the next. The model is having a conversation with itself, building up the information it needs.
This introduced test-time compute as a scaling axis.
Traditional ML says: to make a model smarter, train a larger model. Reasoning models suggest: let the model think longer.
For some problems, a smaller model reasoning 10x longer beats a 10x larger model that answers immediately. Model capability isn’t fixed. It’s partially a function of thinking time.
Reasoning models are not magic. On tasks where the correct abstraction is unknown, or where verification is impossible, longer chains often make things worse, not better. The model can reason confidently toward a wrong answer. But for problems with checkable structure, the gains are real.
2. Training Reasoning: The Art of Building Environments
How do you train a model to reason well?
You can’t just show it examples of good reasoning. The model might mimic surface patterns without learning to think. And for many reasoning tasks, there’s no existing corpus of step-by-step solutions.
The answer that emerged, particularly in DeepSeek’s work, was reinforcement learning with a clever trick: focus on domains where you can verify the answer.
DeepSeek’s R1 model trained primarily on math and code. The reason is straightforward:
- In math, you can verify the solution
- In code, you can run the program.
The training loop: the model generates a reasoning chain and answer. Correct answers reinforce the reasoning. Wrong answers discourage it. Over iterations, the model learns what kinds of reasoning lead to correct answers.
What emerged without being explicitly programmed was fascinating. The model learned to backtrack at dead ends. It learned to verify its own work. It learned to try alternative approaches. These behaviors weren’t hard-coded. They arose purely from the reinforcement signal.
Models trained on code and math didn’t just get better at code and math. They got better at everything. The skills required to solve a math problem are the same skills required for complex instruction following in any domain: parse the request precisely, break it into steps, execute without skipping, check your work, correct errors. A model that learns to work through a multi-step proof has also learned to work through a multi-step business analysis. The reasoning transfers.
Suprisingly the models trained on code and math got better at everything. The skills required to solve a math problem are the same skills required for complex instruction following in any domain: parse the request precisely, break it into steps, execute without skipping, check your work, correct errors. A model that learns to work through a multi-step proof has also learned to work through a multi-step business analysis. The reasoning transfers.
This has a striking implication: RL training on verifiable domains may reduce the need for task-specific fine-tuning. If you want better legal analysis, you might not need legal data. You need a model trained to reason carefully, then provide legal context. The reasoning is general; only the context is specific.
This connects directly to why context engineering became so powerful. When base models improved at following complex instructions, the leverage shifted. You no longer needed to modify weights for domain-specific behavior. You just needed domain-specific context.
The limitation is real: this works for domains with checkable answers, less well for subjective tasks. Writing, analysis, creative work: you can’t just run a verifier. For these, researchers turned to Constitutional AI and RLAIF, where another model provides feedback. Promising but messier.
3. Memory: Context That Persists
Language models historically suffered from amnesia. Every conversation started fresh.
2025 changed that.
OpenAI and Google shipped memory for ChatGPT and Gemini. These systems remember facts across conversations: your preferences, your context. For millions of users, AI assistants became meaningfully personal.
MemGPT (Packer et al., 2023) proposed treating memory like an operating system: fast working memory (the context window) plus slower archival memory (external storage). The system learns to move information between layers, loading relevant memories when needed.
Cognitive Architectures for Language Agents (Sumers et al., 2024) organized memory into types: episodic (what happened), semantic (what things mean), procedural (how to do things).
Anthropic’s Claude Skills took this further: users define reusable instructions that apply across conversations. You specify once (“use this coding style”) and it applies automatically. Same weights, different context, different behavior.
The weights stayed constant while the context evolved entirely.
Memory is another form of context engineering that persists context across time while keeping the model unchanged.
4. Agents: Context From the World
If reasoning is self-generated context and memory is persistent context, agents represent context gathered from the world.
An agent takes actions: searches the web, runs code, calls APIs. Each action produces information that becomes context for the next step.
ReAct (Yao et al., 2022) established the pattern: alternate between thinking and acting. Here’s a simplified example:
User: What's the population of the city where OpenAI is headquartered?
Thought: I need to find where OpenAI is headquartered, then look up population.
Action: search("OpenAI headquarters location")
Observation: OpenAI is headquartered in San Francisco, California.
Thought: Now I need San Francisco's population.
Action: search("San Francisco population 2024")
Observation: San Francisco has approximately 808,000 people as of 2024.
Answer: San Francisco, where OpenAI is headquartered, has about 808,000 people.The model builds context through interaction with tools. Each action fills in information it didn’t have.
In 2025, agents became both more capable and more sobering. Anthropic released Claude with computer use. OpenAI shipped similar capabilities. But Language Agents as Hackers (Yang et al., 2024) showed that even capable agents failed on multi-step tasks requiring genuine problem-solving. They could use tools but lacked strategic thinking over long horizons.
The pattern: agents work well for tasks with clear steps, recoverable errors, frequent feedback. They struggle with long-term planning, irreversible actions, ambiguous goals. Most “agent failures” are actually context failures—the agent had the wrong information at the wrong time.
Deep Research: Agents That Do Your Homework
The most ambitious agent applications fell under “Deep Research”: systems that conduct multi-step research autonomously, producing comprehensive reports.
OpenAI’s Deep Research, Google’s Gemini Deep Research, Perplexity, Grok DeepSearch all shipped in 2025. These aren’t simple RAG. They plan strategies, adapt based on findings, and orchestrate complex workflows.
Deep Research Architecture:
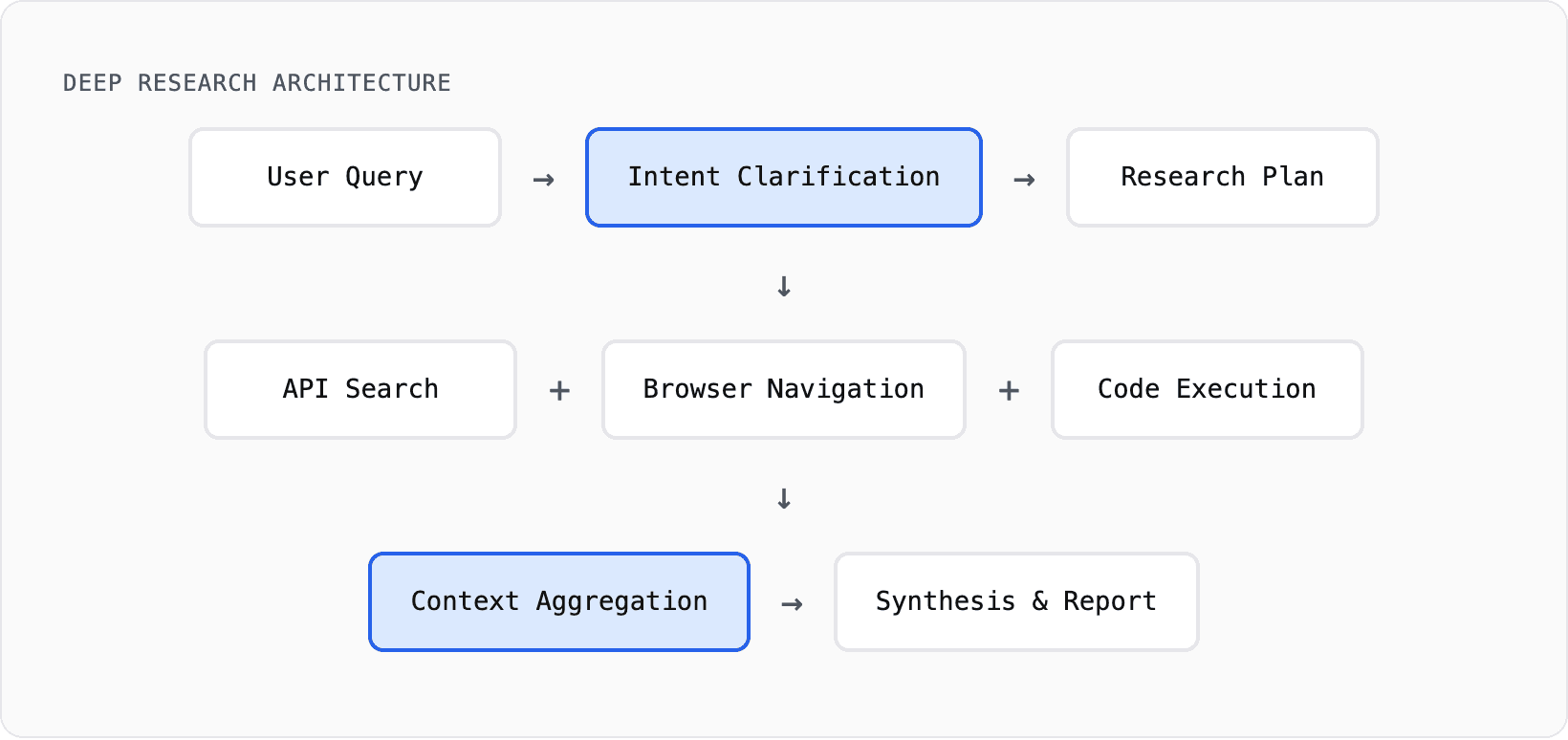
The Model Context Protocol (MCP) emerged as a standard for agents to discover and invoke tools dynamically. The best systems use RL to train agents end-to-end on output quality, not just individual steps.
For information-intensive tasks with clear objectives, autonomous research crossed into usefulness. They struggle with authentication, rapidly changing information, and tasks requiring genuine expertise. But they’ve automated information aggregation.
The End of Naive Fine-Tuning
In 2025, fine-tuning fell out of favor for frontier models. For most teams, it’s now a last resort, not a default.

Several things drove this.
First, frontier models got good enough that fine-tuning often degraded general capabilities.
Second, models got so large that fine-tuning became expensive and slow.
Third, context windows expanded from 4K to 128K, even 1M+. Instruction-following improved dramatically. This just means that if you can describe the task, no need to fine-tune models.
But for most teams: invest in context engineering infrastructure. The ROI is higher, and it transfers when you upgrade base models.
Anthropic illustrates this directly. Rather than fine-tuning Claude for every task, they built a “skills” system: curated instructions for specific domains loaded into context when relevant. Same weights, different context, different behavior.
Nothing changed in the weights. Everything changed in the context.
Voice: The Year It Actually Worked
Voice serves as the delivery layer for context engineering. But delivery matters: context that arrives 2 seconds late is useless. And voice captures richer input than text — tone, hesitation, the rambling that reveals what someone actually thinks.
Context engineering focuses on the right information to the model, while voice focuses on the right information to and from the human, fast enough to matter.
Voice interfaces became genuinely conversational in 2025. The target: under 500ms from when the user stops speaking to when they hear a response.
Two Architectures
Most voice agents use a pipeline: speech-to-text, then LLM, then text-to-speech. The alternative is end-to-end: audio in, audio out. GPT-4o was the breakthrough. Kyutai’s Moshi showed this wasn’t limited to closed models.
Both have tradeoffs. End-to-end preserves more information and achieves lower latency. Pipelines are more flexible: swap components, inspect intermediate text, debug easily. Most production systems still use pipelines.
Latency: The 500ms Barrier
| Component | 2025 Latency | Key Advance |
|---|---|---|
| Speech-to-Text | ~100ms | Streaming (Deepgram, AssemblyAI) |
| LLM Inference | ~200ms | Optimized inference (Groq LPU) |
| Text-to-Speech | ~100ms | Streaming synthesis (Cartesia, ElevenLabs) |
| Total | <500ms | The conversational threshold |
Voice Quality
TTS improved along several dimensions. Emotional range: models learned to convey warmth, concern, excitement. Hume’s EVI explicitly optimized for emotional expressiveness. Prosody got natural: context-aware pacing and emphasis. Voice cloning matured: reasonable custom voices from minutes of audio.
Turn Detection and Interruption
Orchestration, rather than any single component, is the hardest problem.
Turn detection: knowing when the user finished speaking. Wait too long and it feels slow. Jump in early and you cut people off.
Interruption handling: agents now monitor for user speech while generating responses, stopping gracefully when interrupted.
Backchanneling appeared: the “mm-hmm” sounds that signal listening.
A Modern Voice Agent Pipeline
1. Audio capture with echo cancellation
2. Streaming VAD to detect speech boundaries
3. Streaming STT producing partial transcripts
4. Turn detection to decide when user is done
5. LLM inference with transcript and context
6. Streaming TTS as soon as tokens arrive
7. Audio playback with interruption monitoring
8. State management across turns
Frameworks like Pipecat, LiveKit Agents, and Vapi emerged to handle this orchestration, letting developers focus on conversation design.
Voice is about bandwidth. Text is high-effort, low-bandwidth. Voice is lower-effort, higher-bandwidth: ramble, think out loud, convey things that would take paragraphs. Voice captures the actual skill of verbal communication.
An Honest Assessment: Where AI Works, Where It Doesn’t
I’ve painted 2025 as a year of progress, and I believe that. But the ROI is concentrated in specific pockets.
Where AI works well:
[+] Tasks where success is verifiable (code that runs, math that checks)
[+] Tasks where errors are catchable and recoverable
[+] Tasks that augment humans rather than replace them
[+] Tasks where humans review before consequences happen
Where AI still struggles:
[−] Tasks requiring long-horizon planning
[−] Tasks where errors compound silently
[−] Tasks requiring common sense about the physical world
[−] Tasks where you need to know what you don’t know
The pattern: AI is most reliable with tight feedback loops. When you can check output, catch mistakes, and iterate, it works. When AI operates autonomously without supervision, problems accumulate.
Where This Converges: The Reason We Built AmpUp.AI
Once you see the world this way, a certain class of products becomes inevitable.
Sales is the perfect proving ground for context engineering because of its real-time, high-stakes nature.
Sales is a fundamentally verbal skill. Success depends on split-second synthesis: customer signals, product knowledge, competitive positioning. The gap between knowing what to do and doing it under pressure is where deals are won or lost. This is exactly why AI meeting prep has become critical to execution—it lets reps offload the cognitive load of research so they can focus on listening and responding in the moment.
Sales is the ultimate test-time compute environment. A rep has 200 milliseconds to process a “no” and figure out how to turn it into a “yes.” If the AI providing context has 2 seconds of latency, it’s useless. If it doesn’t have the lived context of the last three meetings, it’s dangerous.
We realized that if we could solve context for the world’s most demanding verbal environment, we could solve it for anything.
That’s what we’re building at the AmpUp platform. But the voice agents are only half the story.
AmpUp continuously analyzes sales calls and CRM interactions to extract structured signals across multiple levels:
- Meeting-level: objections raised, commitments made, risk signals surfaced
- Account-level: deal health, MEDDPICC gaps, competitive positioning
- Rep-level: skill patterns, strengths, and coaching priorities
- Org-level: behaviors that drive progression, where deals stall, what the market is signaling
This creates a hierarchical ontology of sales intelligence.
When a rep is about to join a call, we surface not just the notes but also the specific objections this prospect raised last time, how similar deals at this stage typically progress, what this rep specifically needs to work on, and what’s worked for top performers in comparable situations.
The context is structured, layered, and specific to this moment. That context then flows into two applications:
Pre-call preparation: Before a meeting, surface relevant account history, competitive intelligence, and suggested approaches. Not a generic brief. Specific context for this conversation, informed by patterns across thousands of similar interactions.
Deliberate practice: After analyzing call patterns, identify skill gaps and provide low-stakes voice practice against realistic scenarios. The scenarios aren’t generic. They’re generated from the actual objections this rep struggles with, the actual competitive situations they face, the actual gaps in their discovery process.
This works because it sits in the sweet spot:
- Real value: Practice helps, and context-aware practice helps more
- Voice is right modality: Sales is verbal; typing misses most of what matters
- Human in the loop: The point is to train the human, not replace them
- Context engineering as core: The entire platform is about extracting, organizing, and delivering the right context at the right moment
What Most AI Teams Still Get Wrong
After a year of watching teams build with these technologies, patterns emerge. The mistakes are consistent:
-
They optimize prompts instead of systems. A prompt is one piece of context. The retrieval pipeline, the memory architecture, the feedback loops—those determine whether the prompt even matters.
-
They measure accuracy instead of recoverability. In production, errors happen. What matters is whether users can catch them and the system can adapt. A 95% accurate system that fails silently is worse than an 85% accurate system with good error signals.
-
They deploy agents without feedback loops. An agent that can’t learn from its mistakes will keep making them. The best agent systems feed outcomes back into context for the next run.
-
They treat context as text, not state. Context goes beyond words in a prompt—it’s the evolving state of a conversation, a task, a user relationship. Managing that state is the hard engineering problem.
-
They chase model upgrades instead of context upgrades. Switching from GPT-4 to GPT-5 might give you 10% improvement. Fixing your retrieval pipeline might give you 50%. The leverage is asymmetric.
What’s Coming in 2026: The Context Engineering Era
Skill Shift Deepens
Context engineering becomes the most valuable ML skill. Building retrieval, memory, and orchestration matters more than training from scratch.
Smaller Models Punch Up
The DeepSeek lesson compounds. Distillation, MoE, inference optimization keep pushing capability-per-dollar.
Memory Becomes Table Stakes
Users expect AI to remember them. Systems without memory feel broken.
Computer-Use Agents Ship
Agents controlling browsers and applications become useful for bounded workflows.
Voice Goes Primary
For brainstorming, coaching, practice, voice becomes the default interface.
Video and World Models Emerge
OpenAI's Sora, Google's Veo become more capable and integrate with language models.
Multimodal Becomes Normal
The distinction between text/image/audio models blurs. One interaction, multiple modalities.
Enterprise Adoption Accelerates
Mixed results. Success depends on integration work: right use cases, right context systems, feedback loops.
Regulation Starts to Bite
EU AI Act, US state laws come into force. Compliance becomes a real consideration.
For Builders: The Core Message
Focus on context. As models become increasingly commodity, the context system becomes the product.
The technology matured in ways that make it harder to dismiss and easier to use. The hard work of turning this into real value is still ahead.
The next generation of AI builders will call themselves context engineers rather than model trainers.
AmpUp Context Labs
Experience context engineering in practice. Same frontier model, three context configurations, three different capabilities.
Concept Deep-Dive
Explore 2025 AI architectures through Socratic dialogue. Pick a topic from this article.
Sales Roleplay
Practice against a realistic, skeptical buyer. Low stakes, real reps.
Book a Demo with AmpUp
Ready to see how AmpUp can transform your sales team? Schedule a demo with AmpUp and discover how AI-powered sales coaching delivers measurable results.
Frequently Asked Questions
Q: Why is context more important than the model itself?
Because models are becoming commoditized. DeepSeek showed that competitive frontier models can be built for under $6 million. This means the real differentiation isn’t in the weights—it’s in what you feed into them. The context you provide determines whether the model generates insights or hallucinations, whether it applies knowledge accurately or misses nuance. Same model, different context, completely different capabilities.
Q: How does AmpUp apply context engineering to sales?
AmpUp continuously extracts four types of context: static context (your playbooks and company knowledge), retrieved context (customer history and competitive intelligence), generated context (reasoning through deal dynamics), and lived context (memory of interaction patterns with this specific customer). Before every call, we synthesize these into a focused brief that gives reps the exact context they need. This is why reps who use AmpUp preparation systems catch 11-second signals they would normally miss under cognitive load.
Q: If reasoning models let AI think longer, why can’t they just solve sales problems?
Because reasoning is useful for verifiable domains like math and code, but enterprise sales requires judgment about people and relationships—domains where there’s no single “correct answer.” That’s why the best AI systems augment humans rather than replace them. The AI generates context and reasoning, the human makes the judgment call. That combination is how top reps become even better.
Q: What does “context engineering is the real skill now” actually mean for my team?
It means your hiring and training should focus on people who understand how to organize information, design feedback loops, and extract patterns from real interactions. The old skill was writing clever code. The new skill is designing systems that provide the right information at the right time to help humans make better decisions. It’s orchestration, not algorithm design.
Book a demo with us
See how AmpUp turns every call into a coaching opportunity.
Written by

Amit Prakash
Founder & CEO
Amit is the founder and CEO of AmpUp. Previously, he built ThoughtSpot from zero to over $1B in valuation, leading sales and customer success. He's passionate about using AI to eliminate execution variance in sales teams and make every rep perform like the top 10%.

Rahul Goel
Co-founder
Rahul is the co-founder of AmpUp and former Lead for Tool Calling at Gemini. He brings deep expertise in AI systems, reasoning, and context engineering to build the next generation of sales intelligence platforms.
Stay up to date with AmpUp
Follow AmpUp on LinkedInFollow us on LinkedIn for the latest on AI-powered revenue intelligence.